FRTB: Internal Model Approach & Risikomodellierung
Implementierung einer robusten, auf maschinellem Lernen basierenden Risikofaktormodellierung, um die komplexen regulatorischen Anforderungen des Fundamental Review of the Trading Book zu erfüllen.
Ausgangslage
Das Fundamental Review of the Trading Book (FRTB) stellt eine umfassende Überarbeitung der Eigenkapitalanforderungen für das Marktrisiko dar. Finanzinstitute stehen vor der großen rechnerischen Herausforderung, Risikofaktoren präzise zu modellieren, um den Internal Model Approach (IMA) zu erfüllen und ihre Eigenkapitalanforderungen zu optimieren.
Ergebnis
Wir haben eine Python-basierte Pipeline für maschinelles Lernen entworfen und implementiert, um die Bestimmung von Risikofaktoren und die Validierung der Modellierbarkeit zu automatisieren und die Berechnungseingaben nahtlos an die nachgelagerte Engine der Bank zur Berechnung der Eigenkapitalanforderung (Capital Charge) zu liefern.
Detaillierter Bericht
Einführung in das FRTB
Das Fundamental Review of the Trading Book (FRTB) ist ein umfassendes Regelwerk für Eigenkapitalvorschriften, das vom Basler Ausschuss für Bankenaufsicht (BCBS) entwickelt wurde. Als wichtige Säule des Basel-III-Rahmenwerks eingeführt, zielt das FRTB darauf ab, ein widerstandsfähigeres und standardisierteres Marktrisiko-Rahmenwerk zu etablieren. Sein Hauptziel ist es, die in früheren Finanzkrisen aufgedeckten Schwächen zu beheben und sicherzustellen, dass Banken ausreichende Kapitalpuffer gegen Marktschocks vorhalten.
Standardised Approach (SA) vs. Internal Model Approach (IMA)
Unter dem FRTB-Rahmenwerk müssen Finanzinstitute ihre Eigenkapitalanforderungen für Marktrisiken mit einer von zwei Methoden berechnen: dem Standardised Approach (SA) oder dem Internal Model Approach (IMA).
Der Standardised Approach (Standardansatz) ist eine präskriptive, von den Aufsichtsbehörden definierte Formel, die auf standardisierten Risikogewichten basiert. Er ist sehr konservativ und dient sowohl als Basislinie als auch als Rückfallmechanismus. Im Gegensatz dazu erlaubt der Internal Model Approach (IMA) (Interne-Modelle-Ansatz) Banken, ihre eigenen proprietären quantitativen Modelle und historischen Daten zur Berechnung der Eigenkapitalanforderungen heranzuziehen. Dieser Ansatz erfordert eine strenge regulatorische Genehmigung auf Ebene des Trading Desks und schreibt kontinuierliches Performance-Monitoring und Backtesting vor.
Das Ziel des IMA
Das Hauptziel des IMA ist es, ein äußerst risikosensitives Rahmenwerk bereitzustellen. Durch die Nutzung der internen Risikomanagementmodelle einer Bank stimmt der IMA die regulatorischen Eigenkapitalanforderungen viel enger mit den tatsächlichen, granularen wirtschaftlichen Risiken ab, denen eine Bank ausgesetzt ist. Für Institute mit komplexen Handelsgeschäften führt eine erfolgreiche Implementierung des IMA im Allgemeinen zu einer optimierteren und präziseren Eigenkapitalanforderung im Vergleich zu den starren Einschränkungen des Standardised Approach.
Bestimmung der Risikofaktoren und das SSRM
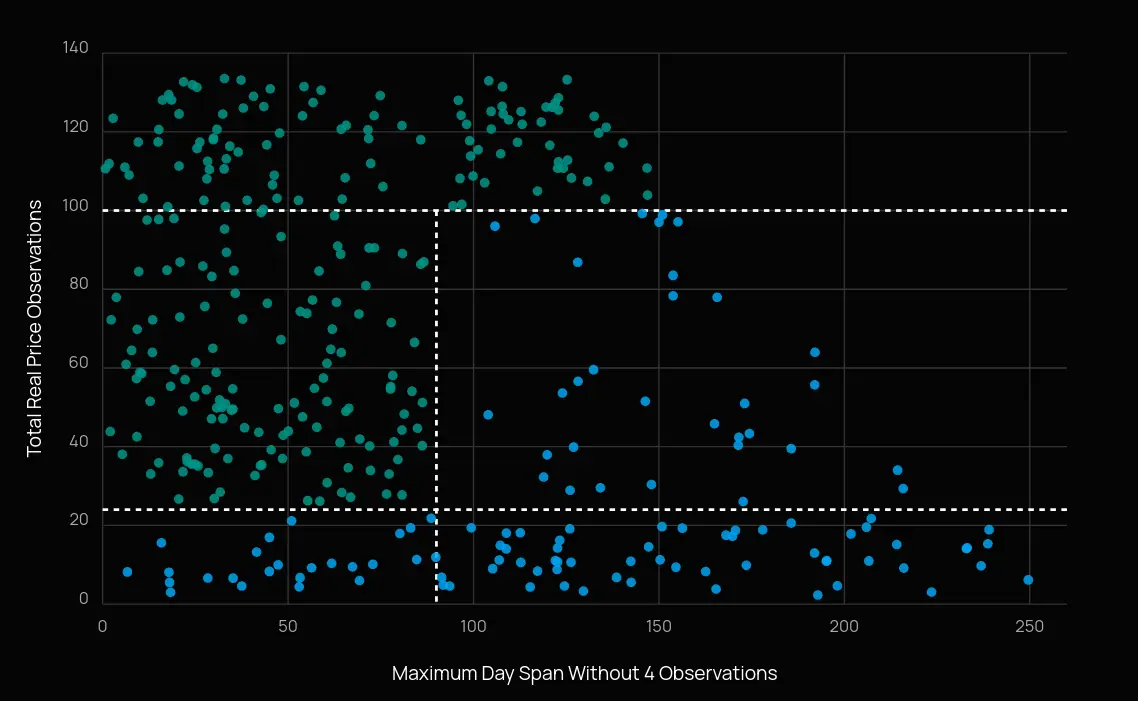
Die erfolgreiche Implementierung des IMA ist ein massives operatives und rechnerisches Unterfangen. Erhebliche Ressourcen müssen in die Bestimmung der Risikofaktoren investiert werden, die das Stressed Scenario Risk Measure (SSRM) direkt beeinflussen, welches letztendlich die endgültige Eigenkapitalanforderung (Capital Charge) diktiert. Die Aufsichtsbehörden fordern eine strikte Kategorisierung dieser Risikofaktoren basierend auf der Liquidität und Beobachtbarkeit der zugrunde liegenden Marktdaten.
Um die Komplexität dieser Klassifizierung zu veranschaulichen, können Sie das interaktive Modell unten verwenden, um die Schwellenwertkriterien anzupassen und zu beobachten, wie sich dies auf die Verteilung von modellierbaren (Modellable) vs. nicht modellierbaren (Non-Modellable) Risikofaktoren auswirkt.
Kapitalunterlegung nicht modellierbarer Risikofaktoren (NMRF)
Wenn ein Risikofaktor die regulatorischen Kriterien der Modellierbarkeit nicht erfüllt, kann er nicht mithilfe des standardmäßigen Expected-Shortfall-Rahmenwerks (ES) einer Bank kapitalisiert werden. Stattdessen müssen Finanzinstitute auf das Stressed Scenario Risk Measure (SSRM) umschwenken. Die Berechnung des SSRM ist ein hochkomplexes, rechenintensives Unterfangen, das darauf ausgelegt ist, Datenunklarheiten zu bestrafen und ausreichende Kapitalpuffer für illiquide Marktvariablen sicherzustellen.
Der Kern dieser Komplexität liegt in der Bestimmung des Extreme Scenario of Future Shock (ESFS). Für jeden einzelnen NMRF müssen Risiko-Engines ein kontinuierliches historisches Beobachtungsfenster von 10 Jahren scannen, um die absoluten Worst-Case-Aufwärts- und Abwärtsschocks über vorgeschriebene Liquiditätshorizonte zu isolieren. Sobald dies identifiziert ist, muss das gesamte betroffene Portfolio unter diesem extremen Szenario neu bewertet werden, um den maximalen potenziellen Verlust zu berechnen.
Diese operative Belastung potenziert sich bei der Aggregation exponentiell. Um den gesamten Stressed Expected Shortfall (SES) zu berechnen, müssen Institute rigoros nachweisen, ob ihre NMRFs idiosynkratisch (unkorreliert) sind. Idiosynkratische Faktoren profitieren von Diversifikation und werden mittels der Quadratwurzel der Summe der Quadrate aggregiert. Korrelierte Faktoren – oder solche, für die kein ausreichender Unabhängigkeitsnachweis vorliegt – müssen jedoch linear aggregiert werden. Dieser einfache Summierungsansatz bietet keinerlei Diversifikationsvorteil und bläht die endgültige Eigenkapitalanforderung (die Own Funds Requirement) drastisch auf.
Wie Maschinelles Lernen helfen kann
Banken greifen in der Regel auf ihre eigenen Handelsdaten für das IMA-Modell zurück. Die Regulierung erlaubt die Nutzung von Drittanbieterdaten, sofern diese vorgegebenen regulatorischen Standards entsprechen. Die Herausforderung besteht darin, zu bestimmen, welche Anlageklassen von Handelsdaten gekauft werden sollen. Um den Return on Investment (ROI) zu maximieren, möchten Banken Handelsdaten erwerben, die ihre eigenen Daten ergänzen, anstatt sie zu duplizieren. Idealerweise führt der Kauf von Handelsdaten dazu, dass nicht modellierbare Risikofaktoren modellierbar werden.
Wir haben diesen intensiven Prozess mithilfe eines fortschrittlichen Python-Tech-Stacks (unter starker Nutzung von pandas, pytorch, numpy und sqlalchemy) in Kombination mit Ansätzen des maschinellen Lernens bewältigt, um entsprechende Handelsdaten-Ziele auszuwählen. Darüber hinaus haben wir eine automatisierte Pipeline entwickelt, die die von der nachgelagerten Engine benötigte Ausführung der Risikofaktor-Schockgenerierung durchführt, um die endgültige Eigenkapitalanforderung zu berechnen.
Weiterführende Literatur & Regulatorische Vorgaben
Für einen tieferen Einblick in die quantitativen Methoden, Proxy-Fallback-Mechanismen und die strengen regulatorischen Erwartungen rund um diese Berechnungen empfehlen wir die Lektüre der offiziellen Dokumentation der Europäischen Bankenaufsichtsbehörde (EBA). Die endgültigen Richtlinien und Formeln, die dieses Rahmenwerk regeln, sind im Final draft Regulatory Technical Standards on the calculation of the stress scenario risk measure under Article 325bk(3) of Regulation (EU) No 575/2013 (Capital Requirements Regulation) der EBA dargelegt.
Wichtige regulatorische Links:
Lizenz
Alle Original-Inhalte von Henrik Lütjeharms stehen unter einer Creative Commons Namensnennung 4.0 International Lizenz.
© 2026 Helionox GmbH.