Reinforcement Learning für dynamische Vermögensoptimierung und Asset-Liability-Management
TD3-Reinforcement-Learning-Agenten zur Optimierung lebenslanger Investment- und Konsumpfade unter stochastischen Lifecycle-Restriktionen.
Ausgangslage
Mertons Portfolio-Framework stößt auf erhebliche Skalierungsbarrieren, sobald reale Lebensereignisse wie Kinder, Gesundheitsschocks, Beförderungen oder Erbschaften, etc. einbezogen werden. Die Evaluierung dieser pfadabhängigen Vektoren erfordert traditionell eine Rückwärtspropagierung vom Todeszeitpunkt bis zur Jugend, wobei an jedem Altersschritt dichte Monte-Carlo-Simulationen durchgeführt werden müssen. Dies führt zum sog. 'Fluch der Dimensionen' (Curse of Dimensionality) und treibt den Bedarf an alternativen Methoden voran, die in der Lage sind, langlaufende (30 bis 60 Jahre) Pensionsverbindlichkeiten effizient zu steuern.
Ergebnis
Um diese Einschränkungen zu adressieren, haben wir einen neuartigen Ansatz untersucht, der auf einem Twin Delayed DDPG (TD3) Reinforcement-Learning-Framework basiert. Anstatt auf starre Zustandsgitter oder Rückwärtsinduktionsschleifen zurückzugreifen, behandelt unser Modell die Asset-Allokation über den Lebenszyklus als kontinuierlichen Markov-Entscheidungsprozess (MDP). Getestet über verschiedene demografische Kohorten hinweg, demonstrierte unser Proof of Concept (PoC) eine stabile Konvergenz (Policy Convergence). Dies zeigt, dass der Agent autonom dynamische Investment- und Konsumentscheidungen optimieren und gleichzeitig strukturelle Verbindlichkeiten matchen kann.
Detaillierter Bericht
Einführung in die Lebenszyklus-Portfolio-Optimierung
Die Kapitalallokation über den menschlichen Lebenszyklus hinweg stellt ein fundamentales Problem der quantitativen Ökonomie dar, das ursprünglich 1969 von Robert Merton formalisiert wurde. In seiner reinsten Form versucht das sog. “Merton-Portfolio-Problem”, die mathematische Strategie zu finden, mit der ein individueller oder institutioneller Asset Manager Vermögen kontinuierlich auf ein risikoreiches und ein risikofreies Asset aufteilt, um den erwarteten lebenslangen Nutzen (Utility) zu maximieren.
Zwischen lehrbuchartigen ökonomischen Abstraktionen und der empirischen Realität gibe es allerdings tiefe Lücken. Traditionelle Modelle setzen glatte, kontinuierliche Übergänge voraus. Das reale Leben ist jedoch von Diskontinuitäten geprägt. Für einen institutionellen Pensionsfonds oder einen privaten Investor werden Vermögenspfade ständig durch nicht-lineare Schocks unterbrochen oder verbessert. So haben abrupte Gesundheitsschocks, berufliche Beförderungen oder der Wunsch nach Kindern einen direkten Einfluss auf das Vermoeegen einer Person.
Sobald diese pfadabhängigen Lebensentscheidungen und langlaufenden Verbindlichkeiten eingeführt werden, versagen klassische geschlossene (analytische) Lösungen. Die Lösung dieser Systeme mittels traditioneller numerischer Methoden erfordert eine immense Rechenarchitektur, die massive, mehrstufige Monte-Carlo-Simulationen an jedem diskreten Altersknoten ausführt und die Berechnungen rückwärts vom Tod bis zur Jugend propagiert. Unser Proof of Concept untersucht, wie Deep Reinforcement Learning hierfür eine flexible und skalierbare Alternative bietet.
Das klassische Merton-Problem
Um die Grenzen traditioneller Lösungen zu verstehen, beginnen wir mit dem Framework der stochastischen Steuerung in kontinuierlicher Zeit. Sei das Gesamtvermögen des Agenten zum Zeitpunkt . Die Vermögensdynamik wird durch eine stochastische Differentialgleichung (SDE) beschrieben:
Wobei:
- : Der risikofreie Zinssatz.
- : Die erwartete Rendite des risikoreichen Assets.
- : Die Volatilität des risikoreichen Assets.
- : Das absolute Kapital, das zum Zeitpunkt im risikoreichen Asset allokiert ist.
- : Die Konsumrate.
- : Eine Standard-Brownsche Bewegung, die die Marktunsicherheit abbildet.
Das Ziel besteht darin, den erwarteten diskontierten Nutzen des Konsums über einen endlichen Horizont (der die Lebensspanne darstellt) plus den Endnutzen des Vermögens (die Bequest- oder Erbschaftsfunktion) zu maximieren:
Wobei den subjektiven Diskontierungsfaktor (die Zeitpräferenzrate) darstellt.
Nutzenfunktionen & Risikoaversion
Die Verhaltenseigenschaften des Investors werden durch seine Nutzenfunktion bestimmt. In unserer explorativen Pipeline haben wir die Umgebung so strukturiert, dass sie die zwei prominentesten Risikoprofile der mathematischen Finanzwissenschaft unterstützt:
- Constant Relative Risk Aversion (CRRA): Setzt voraus, dass die Risikotoleranz des Investors proportional mit dem Vermögen wächst.
Wobei () der Koeffizient der relativen Risikoaversion ist.
- Constant Absolute Risk Aversion (CARA): Setzt voraus, dass die Risikotoleranz unabhängig von der absoluten Vermögensakkumulation bleibt.
Wobei den Koeffizienten der absoluten Risikoaversion darstellt.
Der Fluch der Dimensionen
Unter einer einfachen Asset-Struktur ohne zusätzliches Arbeitseinkommen kann die Wertefunktion analytisch durch Lösen der partiellen Hamilton-Jacobi-Bellman-Differentialgleichung (HJB) abgeleitet werden. In dem Moment, in dem wir jedoch reale Markt- und Lebensfektionen einführen, bricht die analytische Lösbarkeit vollständig zusammen. Der traditionelle Ablauf der dynamischen Programmierung stellt sich wie folgt dar:
Tod (Alter 85) ---> Alter 84 ---> Alter 83 ... ---> Jugend (Alter 25)
| | | |
+--- (Monte-Carlo-Simulation an jedem diskreten Zustandsgitter-Knoten)- Pfadabhängigkeit: Parameter wie eine Beförderung oder eine chronische Krankheit verschieben den zugrunde liegenden Einkommenstrend des Agenten dauerhaft. Dies erfordert das Hinzufügen zusätzlicher Zustandsdimensionen, um die Historie mitzuverfolgen.
- Gitter-Explosion (Grid Explosion): Wenn wir das Problem in Gitter diskretisieren, um eine rückwärtige Induktion der dynamischen Programmierung durchzuführen, führt das Hinzufügen von Zustandsvariablen zu einer exponentiellen Explosion der Knotenanzahl. Erfordert das Vermögen beispielsweise Gitterpunkte, skaliert das Hinzufügen von nur 4 binären Lebensparametern (z. B. Kinderstatus, Gesundheitszustand, Beförderungsstufe, Erbschaftstracking) die Knoten-Evaluierungen pro Altersschritt auf Knoten.
- Verschachtelte Monte-Carlo-Schleifen: Da Erwartungswerte über nicht-lineare Schocks hinweg nicht analytisch berechnet werden können, erfordert jeder einzelne Knoten in diesem Gitter eine verschachtelte Monte-Carlo-Simulation, um die Übergangswahrscheinlichkeiten zum nächsten Altersschritt zu bestimmen.
Diese rechnerische Barriere war der Auslöser für unsere Forschung im Bereich des modellfreien Deep Reinforcement Learning (TD3), welches die gitterbasierte Diskretisierung vollständig umgeht, indem es die Lebensspannen als kontinuierliche Pfade behandelt.
Deep Reinforcement Learning Framework (TD3)
Um die hochdimensionalen, pfadabhängigen Eigenschaften realer Lebenszyklen zu bewältigen, formuliert unser Framework die Asset-Allokation und das Konsumverhalten als modellfreien, kontinuierlichen Markov-Entscheidungsprozess (MDP) um. Anstatt Zustände auf einem starren Gitter zu diskretisieren, interagiert ein Deep-Reinforcement-Learning-Agent (DRL) mit einer kontinuierlichen Simulationsumgebung, beobachtet Übergänge und sammelt Erfahrungen, um seine Strategie nativ zu optimieren.
+-------------------------------------------------------------+
| Umgebung (ENVIRONMENT) |
| Marktdynamik (SDE) + Sozioökonomische Lebensereignisse |
+-------------------------------------------------------------+
^ |
| Portfolio-Allokationen | Zustandsvektor
| & Konsumrate (A_t) | (S_t)
| v
+-------------------------------------------------------------+
| TD3 AGENT |
| Actor Netzwerk =======> Clipped Twin Critics |
+-------------------------------------------------------------+
Formulierung des Markov-Entscheidungsprozesses
Die Umgebung wird durch einen Zeithorizont gesteuert, der dem Finanzjahr einer Person entspricht (). Bei jedem Schritt wird die Interaktion durch ein Tupel parametrisiert:
- Der Zustandsraum (): Ein kontinuierlich-kategorialer Vektor, der den Echtzeit-Finanz- und Demografiestatus der Kohorte erfasst:
- : Aktuelle Vermögensakkumulation.
- : Aktuelles Alter der Person.
- : Dynamisches Arbeitseinkommen oder Renten-Cashflow.
- : Kategoriale Basis der Bildungsausbildung (z. B. High School vs. Universität).
- : Binäre Statusindikatoren zur Verfolgung aktiver Lebensereignisse (z. B. Vorhandensein von Kindern, aktive Gesundheitsschocks, Beförderungsstatus, Erbschaftstracking).
- Der Aktionsraum (): Ein kontinuierlicher Kontrollvektor, der die Entscheidungen des Agenten für diese Periode enthält:
- : Das Allokationsgewicht im risikoreichen Asset (erlaubt bis zu Hebelwirkung/Leverage).
- : Die kontinuierliche Konsumrate für die aktive Periode.
- Die Belohnungsfunktion (Reward Function ): Der Feedback-Mechanismus, der entwickelt wurde, um den mathematischen Nutzen des Konsums zu maximieren, während finanzielle Insolvenz oder das Verfehlen von Verbindlichkeiten bestraft werden:
Wobei die aktive Nutzenfunktion (CRRA oder CARA) darstellt, eine Indikatorfunktion ist, die eine schwere Strafe für den Konkurs auslöst, und eine institutionelle Strafe für nicht gedeckte strukturelle Verbindlichkeiten definiert.
Die Twin Delayed DDPG (TD3) Architektur
Standardalgorithmen für kontinuierliche Aktionsräume wie Deep Deterministic Policy Gradient (DDPG) scheitern in hochvolatilen Finanzumgebungen häufig. DDPG leidet unter einem schweren Optimierungs-Überschätzungstrend (Overestimation Bias), bei dem die Critic-Netzwerke den erwarteten zukünftigen Wert bestimmter Asset-Allokationen systematisch überbewerten. Dies führt zu einer suboptimalen Strategieausrichtung und vorzeitiger Divergenz.
Um ein stabiles Policy-Learning über Horizonte von 30 bis 60 Jahren zu gewährleisten, haben wir eine Twin Delayed DDPG (TD3) Architektur implementiert. TD3 führt drei entscheidende algorithmische Modifikationen ein, um die Approximation der Wertefunktion zu stabilisieren:
1. Clipped Double-Q Learning
Der Agent führt zwei unabhängige Critic-Netzwerke, und , zusammen mit ihren entsprechenden Target-Netzwerken. Bei der Berechnung des Zielwerts für das Bellman-Backup-Update wählt die Architektur den minimalen geschätzten Wert zwischen den beiden Critics:
Wobei der stochastische Diskontierungsfaktor ist. Die Wahl des Minimums wirkt dem Overestimation Bias aktiv entgegen, indem sie konservative Vermögenswachstumsschätzungen gegenüber aggressiven, volatilen Prognosen bevorzugt.
2. Target Policy Smoothing
Finanzmärkte sind verrauscht, was bedeutet, dass sehr ähnliche Zustandsvektoren radikal unterschiedliche Belohnungen hervorrufen können. Um zu verhindern, dass sich die Policy auf enge, hochrentable Trainingspfade überanpasst (Overfitting), fügt TD3 der Zielaktion einen kleinen, abgeschnittenen (clipped) Rauschvektor hinzu:
Dies zwingt die Critic-Netzwerke dazu, ihre Werteoberfläche über eine lokalisierte Aktionsumgebung hinweg zu glätten, wodurch sichergestellt wird, dass winzige Verschiebungen der Portfoliogewichte keine erratischen Sprünge im geschätzten zukünftigen Nutzen verursachen.
3. Verzögerte Policy- & Target-Updates (Delayed Updates)
In einem Asset-Allokation-Framework führt das Aktualisieren des Actor-Netzwerks (Policy), bevor die Critic-Netzwerke die Wertelandschaft präzise kartiert haben, zu hochgradig instabilen Trainingsverläufen. TD3 löst dies, indem es das Actor-Netzwerk und alle Target-Netzwerke mit einer geringeren Frequenz aktualisiert als die Critics (z. B. ein Policy-Update für jeweils zwei Critic-Parameter-Updates). Diese Verzögerung stellt sicher, dass der Actor stets von stabilen, mathematisch fundierten Wertgradienten geleitet wird.
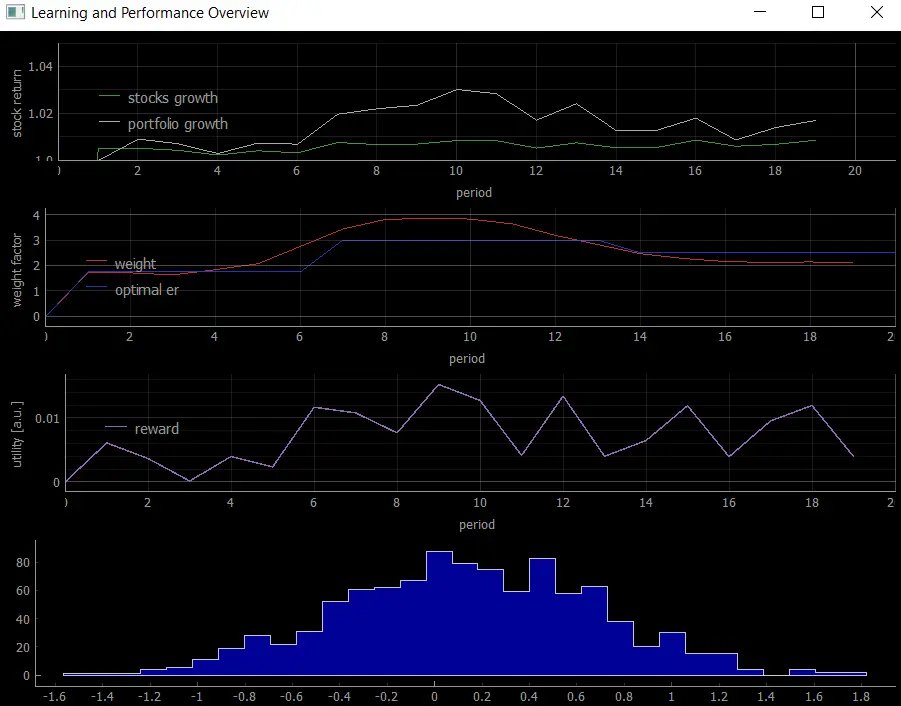
Um die allgemeine Idee unseres Ziels zu veranschaulichen, finden Sie unten ein stark vereinfachtes, interaktives Diagramm, das die Konvergenz eines Actor-Algorithmus gegen das analytisch gelöste Merton-Portfolio-Lebenszyklusproblem darstellt. In jedem Jahr (der gewählten Zeitperiode) beobachtet der Agent den Markt und trifft eine Entscheidung, um einen Teil des Vermögens in Aktien, Anleihen oder Konsum aufzuteilen. Am Ende der Periode erhält der Agent sein Feedback. Dabei fungiert die Nutzenfunktion als Belohnung (Reward), die der Agent für seine Allokationsentscheidung erhält. Eine fundierte Entscheidung erzeugt einen hohen Nutzen, eine schlechte erzeugt einen geringen (oder negativen). Nach ausreichend vielen Trainings-Epochen konvergiert der Agent gegen die optimale Merton-Lösung und zeigt, dass er in der Lage ist, nutzenmaximierende Allokationsentscheidungen zu treffen.
Lizenz
Alle Original-Inhalte von Alexander Thorne stehen unter einer Creative Commons Namensnennung 4.0 International Lizenz.
© 2026 Helionox GmbH.